Easyling Release Notes - 2016. June
Jul 15, 2016 - Easyling.com
June heat has been slowing down development somewhat in Budapest, and this month was heavier on backend improvements and preparation work than it has been on new features being rolled out to the UI. Still, we did manage to complete a few new things, such as wiring up the Client-side Translation feature on the UI (still in beta), rolling out the ability to override content types before translation, and a new crawl interface that allows even more configuration options. See the full details after the jump!
Client-side Translation
JavaScript-powered translation has been in development for some time, but until now, it was available only as a testing tool for our developers. In June, we rolled out the UI, where it has graduated from a testing tool to a beta feature, and our engineers can assist you in creating a JavaScript dictionary of your site, should you be looking to do so.
Content Type Override
By default, the Translation Proxy will not process all available content types, restricting itself to the most common ones, such as “text/html” or “application/javascript”. Sometimes, however, it becomes necessary to support more esoteric types, perhaps proprietary ones. Enter “Content Type Override” rule in Path Settings. With this feature, you can establish mapping from one type to another, allowing the Proxy to modify these fields on the fly, and treat the content as belonging to a different type, one that can be processed (for instance, enforcing plaintext to be treated as JavaScript, which may be used to defeat certain hardening techniques that rely on deliberately using a false content type). Do note, however, that in order to maintain compatibility, all content types must be specified exactly (i.e. pattern matching, globbing, or prefix rules are not supported in the map)!
[caption id="attachment_3061” align="aligncenter” width="706”]
New Crawler Interface
The crawl dialog has also received a rather large facelift, with many new options being added.
For instance, you can now disable the processing of attributes during a crawl. This is most useful when discovering a large site with many images for word count purposes, before the content extraction crawl. By forgoing the processing of images, the number of requests sent (and therefore the time taken) is reduced greatly.
It is now also possible to put a throttle on the crawl by setting the number of simultaneous requests. By default, the proxy sends out eight parallel requests at most, which is also the upper limit of this setting. However, if the server responds with “Too many requests”, you can dial the load back by decreasing this value.
[caption id="attachment_3059” align="aligncenter” width="733”]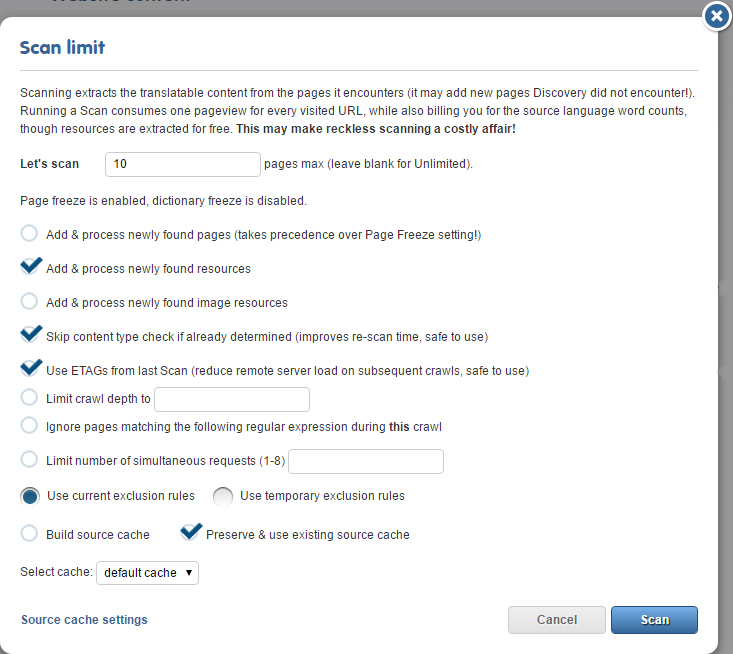
Stay tuned for more interesting features to make website translation easier!